October 21, 2025
“My Bed Won’t Tilt!” Lessons of the Amazon AWS Outage for Customer Experience

Among the gnashing of teeth and mockery on X (Twitter), one of the few services not affected by Amazon’s massive outage, “My bed won’t tilt” isn’t one of the complaints we were expecting to see in relation to yesterday’s Amazon AWS failure.
But for one smart bed company, such is their blind allegiance to the cloud and failure to consider the customer experience, they forgot to develop an offline option. That left Eight Sleep’s CEO sheepishly posting on Twitter that their Pod range of luxury beds were stuck until Amazon’s DNS issue that shut down many online services was resolved.
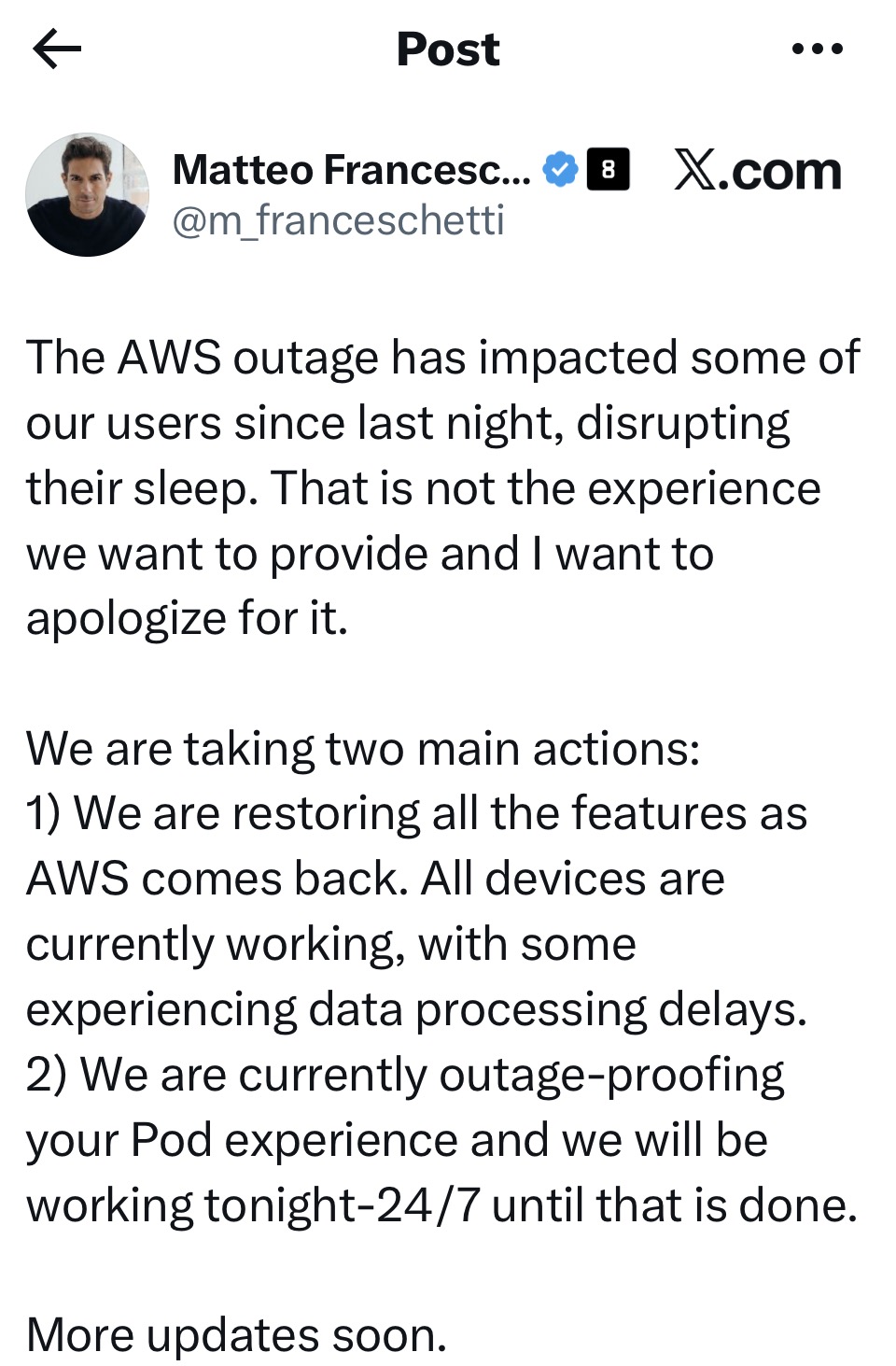
While it might be a little cruel to highlight one company, theirs is a spectacular example of not considering what happens when that little “other” bit of the typical 99.9% uptime service agreement comes home to roost.
The 0.1% of the time struck many companies from social media apps like Snapchat and Reddit, games like Fortnite and Roblox, along with key business apps like Zoom and Canva and with many consumer services.
Back to the Eight Sleep story. Some beds were stuck with the warmers turned on, making them overly toasty for customers.
Other users doing some tech digging found that their beds were sending a whopping 16GB of data a month about their sleeping habits.
The key is that Eight Sleep has an opportunity to fix these issues, sort out the data hogging, and consider their products from the customer angle, not as a sexy big data analytics problem to be solved.
Also, perhaps, customers might want to consider why they are paying a cloud service £33 monthly “Autopilot Plan” fee for a £1,400 to £4,000 bed? Either way, there’s a great case study with lessons for any company that thinks technology-only is the way to go.
When AWS Goes Down, We All Feel Down
Also knocked offline by the outage at the US-EAST-1 data centre were some of Amazon’s own features. Alexa smart speakers and Ring doorbells decided to take the day off, while the likes of Lloyd’s Bank customers and those trying to get hold of HMRC also suffered issues.
Whatever the business, a complete reliance on one service provider creates that single point of failure that will inevitably fail. And if something as simple as a DNS issue at the heart of the Amazon outage can ruin one day’s business, companies need to consider what will happen during something more serious.
To be fair to Amazon, they fixed the problem within three hours, but the lag and capacity errors and the huge backlog meant it took some time for the problem to totally clear.
Whether it is another Amazon, Google or Microsoft Azure problem in future, the tech vendors and companies that rely on them need greater redundancy and failover support to keep systems running. Smarter IT people than us will know the details, but getting those changes in motion should be an easy win today.
For CX types, consider the millions of DuoLingo users for whom the app came back in time for many to continue their streaks. Imagine the outrage if it had lasted for a full day?


