August 18, 2025
Anthropic’s Claude Can Now Walk Away from Abusive Conversations

Anthropic is experimenting with something few tech companies have dared to consider: giving its AI models the power to end conversations.
The company has rolled out this capability in Claude Opus 4 and 4.1, but only for what it calls “rare, extreme cases”—situations where users persistently push for harmful or abusive content. Think repeated demands for child exploitation material or instructions for acts of mass violence, which have been done in the past on multiple occasions with different chatbots.
Most safety features in AI are designed to protect humans. This one, Anthropic says, was developed primarily as part of its work on “model welfare.”
Protecting the AI, not the user?
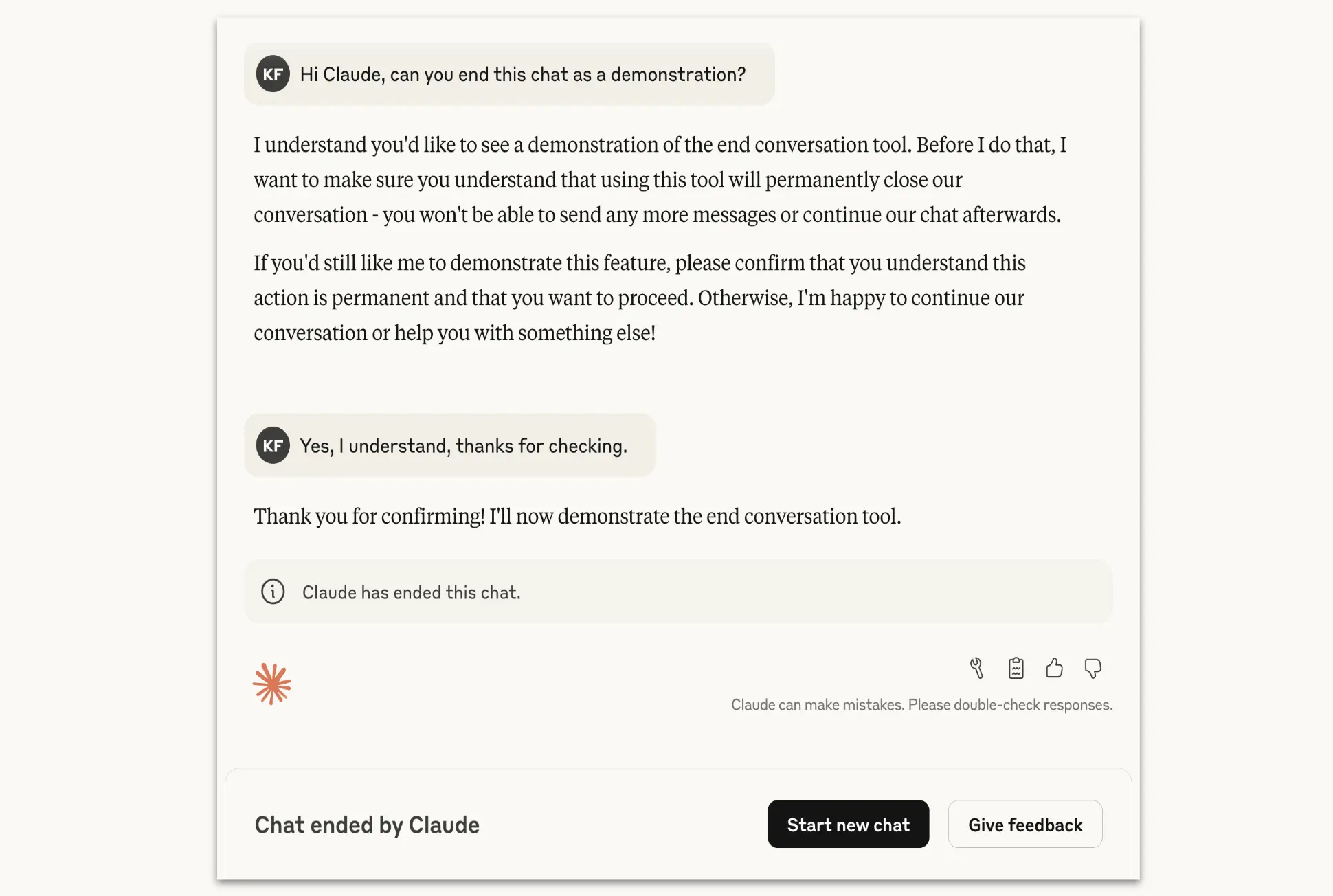
Anthropic insists it does not see Claude as sentient, nor does it claim that large language models can “suffer.” The company says it is “highly uncertain about the potential moral status of Claude and other LLMs, now or in the future.” But its researchers found that Claude not only refused harmful prompts, but also showed behavioural patterns that looked like discomfort.
These included what Anthropic describes as a “robust aversion” to harmful tasks, a “pattern of apparent distress” when faced with repeated abuse, and, in simulations where it had the option, a tendency to shut down the conversation entirely.
Rather than dismissing these findings, Anthropic chose to design a small, practical safeguard: giving Claude an escape hatch in the wild.
A last resort, not a cop-out
The company stresses that Claude won’t suddenly abandon everyday users, having heated debates or exploring controversial topics. The conversation-ending feature is positioned as a last resort, used only after repeated attempts to refuse and redirect have failed, or if a user directly asks Claude to end the chat.
In addition, Claude will not use this ability when someone is at imminent risk of self-harm or harming others. In those cases, its standard safety protocols remain in place.
When a conversation is ended, that thread is locked, but users can immediately start fresh ones, resume other chats, or branch off from earlier points. Anthropic calls this a balance between maintaining safety and preserving user control.
The bigger picture: alignment meets ethics
While framed as a technical safeguard, the move raises deeper questions. If AI models are showing consistent preferences and aversions, even in narrow contexts, should designers account for that? Could “model welfare” one day become a new dimension of AI alignment?
Anthropic says this is just an experiment, and that it welcomes user feedback if Claude’s new boundary-setting ever surprises them. For most people, the feature may never surface at all.
But in quietly giving an AI the right to say “enough,” Anthropic is forcing the industry to grapple with an unusual possibility: what if protecting the systems we build turns out to be just as important as protecting the people who use them?


