July 07, 2025
Qualtrics X4 London Highlights the Power of Synthetic Data

Under sunny skies at a restored part of London’s Tobacco Docks, 1,500 Qualtrics clients, customers, CXM and prospects recently lapped up the insights from experience management experts. Check out the short video to get a feel of the event that was high on enthusiasm for making life better for customers and transforming whole companies into customer-centric organisations.
During his keynote, Qualtrics CEO Zig Serafin highlighted how a new generation of AI agents will anticipate and tailor responses to better meet customer needs, while businesses now expect AI tools that help improve their brand voice.
Through sentiment and predictive analysis, AI gains a better understanding of attitude, emotion, and opinion from feedback. The new super-power for Qualtrics Edge – Qualtrics’ market research capability – is Instant Insights from synthetic data, which enables the simulation of immediate customer responses to marketing or brand ideas. After a day of interviews, product demos, lightning talks and sessions, Ken Hughes gave a rip-roaring closing speech, discussing how the lessons from Taylor Swift’s personal marketing can be applied, but that’s another article!
Talking Synthetic Customers with Ali Henriques

During the day, Qualtrics’ Ali Henriques, Executive Director of Qualtrics Edge, gave CXM an interview with plenty of insights into the power, risks, benefits and challenges of synthetic data.
Before the questions started, she warned that “We should approach AI with enthusiasm and a healthy degree of scepticism. And asked companies to ask dozens of questions about AI, because all it takes is one bad go at the technology to ruin a project.”
What is synthetic data? And is yours the same as NVIDIA’s self-driving car synthetic data, etc.?
“The term is one we as an industry have borrowed, so it has many uses. But ours refers to synthetic survey and response data. For instance, if a company wants insight into who drank canned water this week, our synthetic panel can respond – no need for 40-question surveys that take 20 minutes to complete. No wonder real respondents were getting frustrated.
“If we can use synthetic data to streamline the design phase, we can create shorter, sharper surveys for real respondents, and pay them a decent dollar for their time. That’s a win for everyone.
“A component of the training data is survey data, from survey responses. It is not intended to represent operational data or purchase data. However, there is human behaviour in the sentiment data that we are training, and then using it to simulate what certain populations would say.”
CXM: My mental image is of a pen of keen little AI characters, ready to leap into an interview situation and give different answers.
“I love that. That is roughly what they’re doing in there. Because what we’re doing, just as you do with a human based panel study today, is say, ‘I want 500 canned water consumers from the UK’. We’ll do the exact same.”
“We are taking attitudes, interests, beliefs and behaviours, and we’re representing those with our model. We are being specific and we’re studying our quotas and screeners as we always have. What’s important is that we are generating unique, unduplicated responses.”
How did the Booking.com synthetic data pilot go?
“I spent nights and weekends with Eline Metske (Senior Researcher) at Booking.com reviewing these results. We learned how important word choice is, not only in human versus synthetic, but just in general. As we design studies, we imply a lot of meaning. And, we also interpret meaning very differently, probably all of us would interpret one question very differently when we think about it.
“Our work in tuning is to teach the model that when we ask questions like, ‘on a scale of x to y’, or ‘how well does this statement describe you’, we’re all trying to get at the same thing. Don’t worry about the semantic choices of the question. Instead, focus on that statement and represent your persona.
“So many great learnings and there were a couple of examples where AI totally failed us. And we’ve used that as great feedback, but plenty of others where Booking.com gained valuable operational data.”
Is synthetic being leapt on by smaller companies, younger companies and startups without the resources of larger organisations?
“I can classify our clients into enterprise, corporate and academic/public sectors, and the greatest demand is coming from corporate. However, we’re now starting to see the beginnings of enterprise really knocking down our doors.
“I’ve seen requests for information from massive global enterprises for synthetic data providers. What they’re doing is trying to control how synthetic research is used across the business. I’ve seen a lot of interest, if I compare over the course of the past six months. There was some resistance, and now it’s absolute curiosity with healthy scepticism. They have a lot of really good questions.”

How is Qualtrics providing synthetic?
“To clarify what we’re selling: we provide our customers with subscriptions to Edge audiences. They can still use their subscription to access humans for research, but a minimum of 10% of those credits must be used for synthetic research. We are also expanding beyond that base into a second tranche of businesses with specific purchase behaviours.
“What will be interesting to see is what businesses do with their access to these credits. Right now they may only want to use them on human research, but by the end of their one year contract term, how many more responses are they collecting through synthetic respondents? Maybe more than they might have initially budgeted. That’s absolutely something we are awaiting.”
How do you keep your data fresh?
“We use the phrase, ‘hydration’. We tap into generic LLMs that provide fresh data – for example, the day’s news, external factors that might be influencing your world, your market, your industry. On top of that, we have a layer of Qualtrics proprietary data. Our data is commissioned, aggregated and anonymised, so that it is allowed to be used for the purposes of training. The training data source is a longitudinal study that asks the same questions about attitudes, preferences, and interests as a consistent clean set of data per market, to feed our model.
“This means the data has a reliable source to see how things move over time. In addition to our own longitudinal studies, we also pay for non-survey based data, so things like in-person behavioural data, physical visitation, web app, usage, search, transaction, as additional signals for movement within categories and spaces, and all of that is what keeps it fresh. My team runs roughly 10,000 projects with 10 million responses every year. We need to continue to invest in these longitudinal studies from humans to keep our data fresh.”
Is there an ethical flag that would pop up if people’ start asking the system odd questions?
“I’m glad you asked. Yes, just this weekend we have a slack thread of all things synthetic, and it’s so fun. Our president of AI, and his team are already developing ethical safeguards. And there are workflows in place, even before commercial release, to flag sensitive topics we refuse to simulate. Plus, every subscription includes a value manager who can advise if a request isn’t a good fit for synthetic research. So there’s some help to keep marketers on the right track and providing insights that are a good fit against the ones that aren’t, so that you don’t waste your credits. Things get a little bit harder when you can go directly to the source, but we’ll build in these layers.”
And so he’s already got work flows for the layers, because it’s not commercially available yet. But we have protections for sensitive topics, you know, studying types that we just categorise that we absolutely refuse to thematically generate.
What’s the standout or wow moment, where synthetic insights have provided something amazing that no one was expecting?
“I love that question so much. There’s two, if you’ll allow me. One, a big management consulting company. When we first previewed the side-by-side human versus synthetic results for them, someone on my team said to them, ‘You’ve been quiet. Do you have any questions?’. We’re all nervous, right? And the client goes, ‘I’m going to need a moment. I think I’ve just witnessed something monumental.’
“It was a literal goosebumps moment. He later presented the results at a major European conference and told his team: ‘This could completely change how we work.’ Their measure of success was simple: would we have made the same decisions using synthetic responses as we would with human data? In nearly 90% of cases – yes.
“The other for me was with Booking.com, and this will appeal to the hard core customer researchers out there that aren’t willing to let go of surveys just yet. Our work with Booking.com showed word choice really matters. We can get lazy, take shortcuts, and we try to be colloquial. We use vague terms like, ‘What does reliability mean?’, but synthetic research shines a light on these weaknesses in the process, in a way that I wasn’t expecting.
“Within just a short few years, we can expect to move past surveys. That’s going to happen, not for everything, but people will just ask synthetics what they think about a certain product. You get quick reactions and you can iterate. You might still choose to invest in some one-on-one or in-home usage testing of that product, but we’ll have conversations with the data at a higher level before going deep into surveys. Right now, surveys are all we have. We can Google, we can use ChatGPT, but we still need surveys.”
Check back soon for more customer interviews from the Qualtrics X4 event.
*This interview has been edited for clarity and brevity
Bonus: Trends in CX From Qualtrics
The key message, among the product updates including Experience Agents as part of the broader shift to AI, was the need to deliver a strong employee experience that can deliver a great CX. Software can help drive change, but leadership, understanding and empathy remain inherently human parts of the process.
News from the event included Qualtrics’ 2025 Customer Experience Trend report highlighting falling trust, satisfaction, recommendations and sales among European consumers.
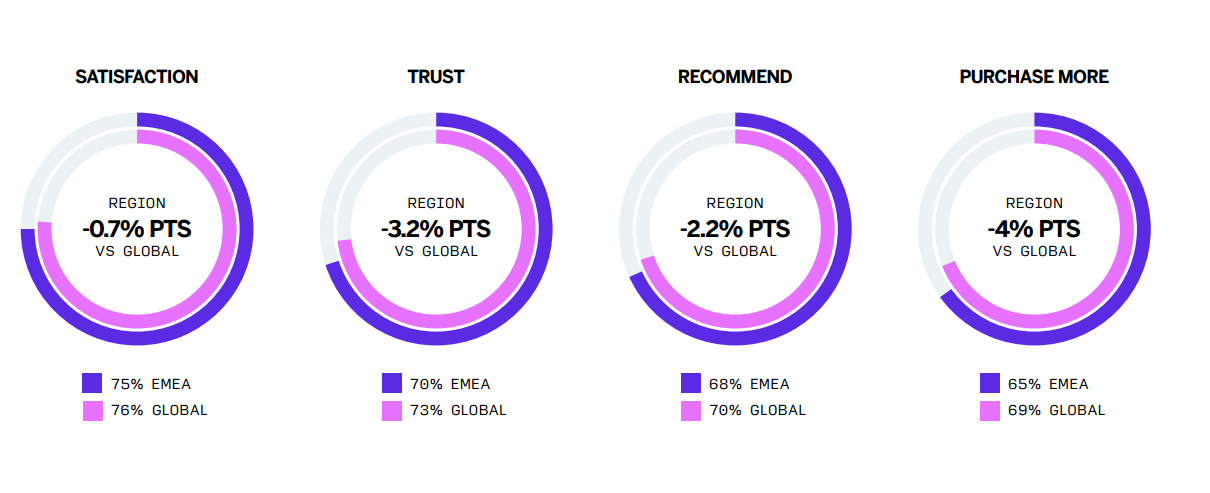
Trends from the research include a move from AI hype to scepticism, declining consumer loyalty due to inflated expectations and a consumer market that wants companies to go back to basics.


